5.3. Example 2 - Longslit large-dither point source - using the “Reduce” class
A reduction can be initiated from the command line as shown in Example 2 - Longslit large-dither point source - using the “reduce” command line and it can also be done programmatically as we will show here. The classes and modules of the RecipeSystem can be accessed directly for those who want to write Python programs to drive their reduction. In this example, we replicate the command line version of Example 2 but using the Python programmatic interface. What is shown here could be packaged in modules for greater automation.
5.3.1. The dataset
If you have not already, download and unpack the tutorial’s data package. Refer to Downloading tutorial datasets for the links and simple instructions.
The dataset specific to this example is described in:
Here is a copy of the table for quick reference.
Science |
S20220611S0717 (705 nm)
S20220611S0716 (795 nm)
|
Science biases |
S20220610S0182-186
S20220611S0827,829,830,832,834
|
Science flats |
S20220611S0718 (705 nm)
S20220611S0715 (795 nm)
|
Science arcs |
S20220611S0782 (705 nm)
S20220611S0779 (795 nm)
|
Standard (LTT7379) |
S20220608S0098 (705 nm)
S20220608S0101 (795 nm)
|
Standard biases |
S20220608S0186-190
S20220609S0206-210
|
Standard flats |
S20220608S0099 (705 nm)
S20220608S0100 (795 nm)
|
Standard arc |
S20220608S0124 (705 nm)
S20220608S0125 (795 nm)
|
BPM |
bpm_20220128_gmos-s_Ham_22_full_12amp.fits
|
5.3.2. Setting up
First, navigate to your work directory in the unpacked data package.
cd <path>/gmosls_tutorial/playground
The first steps are to import libraries, set up the calibration manager, and the logger.
5.3.2.1. Configuring the interactive interface
In ~/.dragons/, add the following to the configuration file dragonsrc:
[interactive]
browser = your_prefered_browser
The [interactive] section defines your prefered browser. DRAGONS will open
the interactive tools using that browser. The allowed strings are “safari”,
“chrome”, and “firefox”.
5.3.2.2. Importing libraries
1import glob
2import astrodata
3import gemini_instruments
4from recipe_system.reduction.coreReduce import Reduce
5from gempy.adlibrary import dataselect
The dataselect module will be used to create file lists for the
biases, the flats, the arcs, the standard, and the science observations.
The Reduce class is used to set up and run the data
reduction.
5.3.2.3. Setting up the logger
We recommend using the DRAGONS logger. (See also Double messaging issue.)
6from gempy.utils import logutils
7logutils.config(file_name='gmosls_tutorial.log')
5.3.2.4. Set up the Calibration Service
Important
Remember to set up the calibration service.
Instructions to configure and use the calibration service are found in Setting up the Calibration Service, specifically these sections: The Configuration File and Usage from the API.
5.3.3. Create file lists
The next step is to create input file lists. The module dataselect helps
with that. It uses Astrodata tags and descriptors to select the files and
store the filenames to a Python list that can then be fed to the Reduce
class. (See the Astrodata User Manual for information about Astrodata and for a list
of descriptors.)
The first list we create is a list of all the files in the playdata/example2
directory.
11all_files = glob.glob('../playdata/example2/*.fits')
12all_files.sort()
We will search that list for files with specific characteristics. We use
the all_files list as an input to the function
dataselect.select_data() . The function’s signature is:
select_data(inputs, tags=[], xtags=[], expression='True')
We show several usage examples below.
5.3.3.1. Two lists for the biases
We have two sets for biases: one for the science observation, one for the spectrophotometric standard observation. The science observations and the spectrophotometric standard observations were obtained using different regions-of-interest (ROI). So we will need two master biases, one “Full Frame” for the science and one “Central Spectrum” for the standard.
To inspect data for specific descriptors, and to figure out how to build
our dataselect expression, we can loop through the biases and print the value
for the descriptor of interest, here detector_roi_setting.
13all_biases = dataselect.select_data(all_files, ['BIAS'])
14for bias in all_biases:
15 ad = astrodata.open(bias)
16 print(bias, ' ', ad.detector_roi_setting())
../playdata/example2/S20220608S0186.fits Central Spectrum
../playdata/example2/S20220608S0187.fits Central Spectrum
../playdata/example2/S20220608S0188.fits Central Spectrum
../playdata/example2/S20220608S0189.fits Central Spectrum
../playdata/example2/S20220608S0190.fits Central Spectrum
../playdata/example2/S20220609S0206.fits Central Spectrum
../playdata/example2/S20220609S0207.fits Central Spectrum
../playdata/example2/S20220609S0208.fits Central Spectrum
../playdata/example2/S20220609S0209.fits Central Spectrum
../playdata/example2/S20220609S0210.fits Central Spectrum
../playdata/example2/S20220610S0182.fits Full Frame
../playdata/example2/S20220610S0183.fits Full Frame
../playdata/example2/S20220610S0184.fits Full Frame
../playdata/example2/S20220610S0185.fits Full Frame
../playdata/example2/S20220610S0186.fits Full Frame
../playdata/example2/S20220611S0827.fits Full Frame
../playdata/example2/S20220611S0829.fits Full Frame
../playdata/example2/S20220611S0830.fits Full Frame
../playdata/example2/S20220611S0832.fits Full Frame
../playdata/example2/S20220611S0834.fits Full Frame
We can clearly see the two groups of biases above. Let’s split them into two lists.
17biasstd = dataselect.select_data(
18 all_files,
19 ['BIAS'],
20 [],
21 dataselect.expr_parser('detector_roi_setting=="Central Spectrum"')
22)
23
24biassci = dataselect.select_data(
25 all_files,
26 ['BIAS'],
27 [],
28 dataselect.expr_parser('detector_roi_setting=="Full Frame"')
29)
Note
All expressions need to be processed with dataselect.expr_parser.
5.3.3.2. A list for the flats
The GMOS longslit flats are not normally stacked. The default recipe does not stack the flats. This allows us to use only one list of the flats. Each will be reduced individually, never interacting with the others.
30flats = dataselect.select_data(all_files, ['FLAT'])
5.3.3.3. A list for the arcs
The GMOS longslit arcs are not normally stacked. The default recipe does not stack the arcs. This allows us to use only one list of arcs. Each will be reduced individually, never interacting with the others.
31arcs = dataselect.select_data(all_files, ['ARC'])
5.3.3.4. Two lists for the spectrophotometric standard star
If a spectrophotometric standard is recognized as such by DRAGONS, it will
receive the Astrodata tag STANDARD. To be recognized, the name of the
star must be in a lookup table. All spectrophotometric standards normally used
at Gemini are in that table.
For this example with a large wavelength dither, we will be reducing the standard star observations at each central wavelength separately without stacking them. The standard star reduction recipe stacks all the observations in a given file list. So we need to create separate file lists for the different central wavelengths.
First, let’s inspect the central wavelength of the standard star frames in our raw data directory.
For this, we can loop through all the files with the tag STANDARD and print
the value for the descriptor of interest, here central_wavelength.
32all_stdstar = dataselect.select_data(all_files, ['STANDARD'])
33for std in all_stdstar:
34 ad = astrodata.open(std)
35 print(std, ' ', ad.central_wavelength())
../playdata/example2/S20220608S0098.fits 7.05e-07
../playdata/example2/S20220608S0101.fits 7.95e-07
We will then create two standard star lists for the two central wavelengths.
36stdstar_705nm = dataselect.select_data(
37 all_files,
38 ['STANDARD'],
39 [],
40 dataselect.expr_parser('central_wavelength==7.05e-07')
41)
42
43stdstar_795nm = dataselect.select_data(
44 all_files,
45 ['STANDARD'],
46 [],
47 dataselect.expr_parser('central_wavelength==7.95e-07')
48)
5.3.3.5. A list for the science observations
The science observations are what is left, that is anything that is not a
calibration. Calibrations are assigned the astrodata tag CAL, therefore
we can select against that tag to get the science observations.
First, let’s have a look at the list of objects.
49all_science = dataselect.select_data(all_files, [], ['CAL'])
50for sci in all_science:
51 ad = astrodata.open(sci)
52 print(sci, ' ', ad.object())
On line 49, remember that the second argument contains the tags to include
(tags) and the third argument is the list of tags to exclude
(xtags).
../playdata/example2/S20220611S0716.fits ORC5
../playdata/example2/S20220611S0717.fits ORC5
In this case we only have one target. If we had more than one, we would need
several lists and we could use the object descriptor in an expression. We
will do that here to show how it would be done. To be clear, the
dataselect.expr_parser argument is not necessary in this specific case.
53scitarget = dataselect.select_data(
54 all_files,
55 [],
56 ['CAL'],
57 dataselect.expr_parser('object=="ORC5"')
58)
5.3.4. Bad Pixel Mask
Starting with DRAGONS v3.1, the static bad pixel masks (BPMs) are now handled as calibrations. They are downloadable from the archive instead of being packaged with the software. They are automatically associated like any other calibrations. This means that the user now must download the BPMs along with the other calibrations and add the BPMs to the local calibration manager.
See Getting Bad Pixel Masks from the archive in Tips and Tricks to learn about the various ways to get the BPMs from the archive.
To add the BPM included in the data package to the local calibration database:
59for bpm in dataselect.select_data(all_files, ['BPM']):
60 caldb.add_cal(bpm)
5.3.5. Master Bias
We create the master biases with the Reduce class. We will run it
twice, once for each of the two raw bias lists. The master biases
will be automatically added to the local calibration manager when the “store”
parameter is present in the .dragonsrc configuration file.
The output is written to disk and its name is stored in the Reduce
instance. The calibration service expects the name of a file on disk.
Because the database was given the “store” option in the dragonsrc file,
the processed biases will be automatically added to the database at the end
of the recipe.
61reduce_biasstd = Reduce()
62reduce_biassci = Reduce()
63reduce_biasstd.files.extend(biasstd)
64reduce_biassci.files.extend(biassci)
65reduce_biasstd.runr()
66reduce_biassci.runr()
The two master biases are: S20220608S0186_bias.fits and
S20220610S0182_bias.fits.
Note
The file name of the output processed bias is the file name of the
first file in the list with _bias appended as a suffix. This is the
general naming scheme used by the Recipe System.
Note
If you wish to inspect the processed calibrations before adding them
to the calibration database, remove the “store” option attached to the
database in the dragonsrc configuration file. You will then have to
add the calibrations manually following your inspection, eg.
caldb.add_cal(reduce_biasstd.output_filenames[0])
caldb.add_cal(reduce_biassci.output_filenames[0])
5.3.6. Master Flat Field
GMOS longslit flat fields are normally obtained at night along with the observation sequence to match the telescope and instrument flexure. The matching flat nearest in time to the target observation is used to flat field the target. The central wavelength, filter, grating, binning, gain, and read speed must match.
Because of the flexure, GMOS longslit flat fields are not stacked. Each is reduced and used individually. The default recipe takes that into account.
We can send all the flats, regardless of characteristics, to Reduce and each
will be reduced individually. When a calibration is needed, in this case, a
master bias, the best match will be obtained automatically from the local
calibration manager.
67reduce_flats = Reduce()
68reduce_flats.files.extend(flats)
69reduce_flats.runr()
The primitive normalizeFlat used in the recipe has an interactive mode.
To activate the interactive mode:
70reduce_flats = Reduce()
71reduce_flats.files.extend(flats)
72reduce_flats.uparms = dict([('interactive', True)])
73reduce_flats.runr()
The interactive tools are introduced in section Interactive tools.
Note
If the database is not set to “store” automatically, the processed flats can be added manually as follows:
for f in reduce_flats.output_filenames:
caldb.add_cal(f)
5.3.7. Processed Arc - Wavelength Solution
GMOS longslit arc can be obtained at night with the observation sequence, if requested by the program, but are often obtained at the end of the night or the following afternoon instead. In this example, the arcs have been obtained at night, as part of the sequence. Like the spectroscopic flats, they are not stacked which means that they can be sent to reduce all together and will be reduced individually.
The wavelength solution is automatically calculated and the algorithm has
been found to be quite reliable. There might be cases where it fails; inspect
the RMS of determineWavelengthSolution in the
logs to confirm a good solution.
74reduce_arcs = Reduce()
75reduce_arcs.files.extend(arcs)
76reduce_arcs.runr()
The primitive determineWavelengthSolution used in the recipe has an
interactive mode. To activate the interactive mode:
77reduce_arcs = Reduce()
78reduce_arcs.files.extend(arcs)
79reduce_arcs.uparms = dict([('interactive', True)])
80reduce_arcs.runr()
The interactive tools are introduced in section Interactive tools.
5.3.8. Processed Standard - Sensitivity Function
The GMOS longslit spectrophotometric standards are normally taken when there is a hole in the queue schedule, often when the weather is not good enough for science observations. For a large wavelength dither, i.e., a difference in central wavelength much greater than about 10 nm, a spectrophotometric standard should be taken at each of those positions to calculate the respective sensitvity functions. The latter will then be used for spectrophotometric calibration of the science observations at the corresponding central wavelengths.
The reduction of the standard will be using a BPM, a master bias, a master flat,
and a processed arc. If those have been added to the local calibration
manager, they will be picked up automatically. The output of the reduction
includes the sensitivity function and will be added to the calibration
database automatically if the “store” option is set in the dragonsrc
configuration file.
The 705nm Standard
In most situation, the default recipe and input parameters will yield a good calculation of the sensitivity function.
81reduce_std_705nm = Reduce()
82reduce_std_705nm.files.extend(stdstar_705nm)
83reduce_std_705nm.runr()
However, if you suspect a suboptimal reduction or just want to confirm that
things are going well, there are four primitives in the default recipe for
spectrophotometric standard have an interactive interface:
skyCorrectFromSlit, findApertures,
traceApertures, and calculateSensitivity. To activate the interactive
mode for all four:
84reduce_std_705nm = Reduce()
85reduce_std_705nm.files.extend(stdstar_705nm)
86reduce_std_705nm.uparms = dict([('interactive', True)])
87reduce_std_705nm.runr()
Since the standard star spectrum is bright and strong, and the exposure short, it is somewhat unlikely that interactivity will be needed for the sky subtraction, or finding and tracing the spectrum. The fitting of the sensitivity function however can sometimes benefit from little adjustment.
To activate the interactive mode only for the measurement of the sensitivity function:
88reduce_std_705nm = Reduce()
89reduce_std_705nm.files.extend(stdstar_705nm)
90reduce_std_705nm.uparms = dict([('calculateSensitivity:interactive', True)])
91reduce_std_705nm.runr()
The interactive tools are introduced in section Interactive tools.
The 795nm Standard
For the standard star observation at central wavelength 795 nm in this
dataset, calculateSensitivity with its default parameter values yields a suboptimal number
of data points to constrain its sensitivity curve (see the left plot below; click the panel to enlarge).
There is a conspicuous gap between 820 and 880 nm – a result of the amplifier #5 issue and compounded
by the presence of telluric absorption redward of around 930 nm.
To deal with this, we can consider interpolating the (reference) data of the spectrophotometric standard,
given that it has a smooth spectrum,
to generate new sensitivity data points to fit.
This is enabled by the resampling parameter, whose value
we update as follows
92reduce_std_795nm = Reduce()
93reduce_std_795nm.files.extend(stdstar_795nm)
94reduce_std_795nm.uparms = dict([('calculateSensitivity:interactive', True),
95 ('calculateSensitivity:resampling', 15.0)
96])
97reduce_std_795nm.runr()
The resulting curve is shown on the right plot (click the panel to enlarge). Notice that we have manually masked three data points.
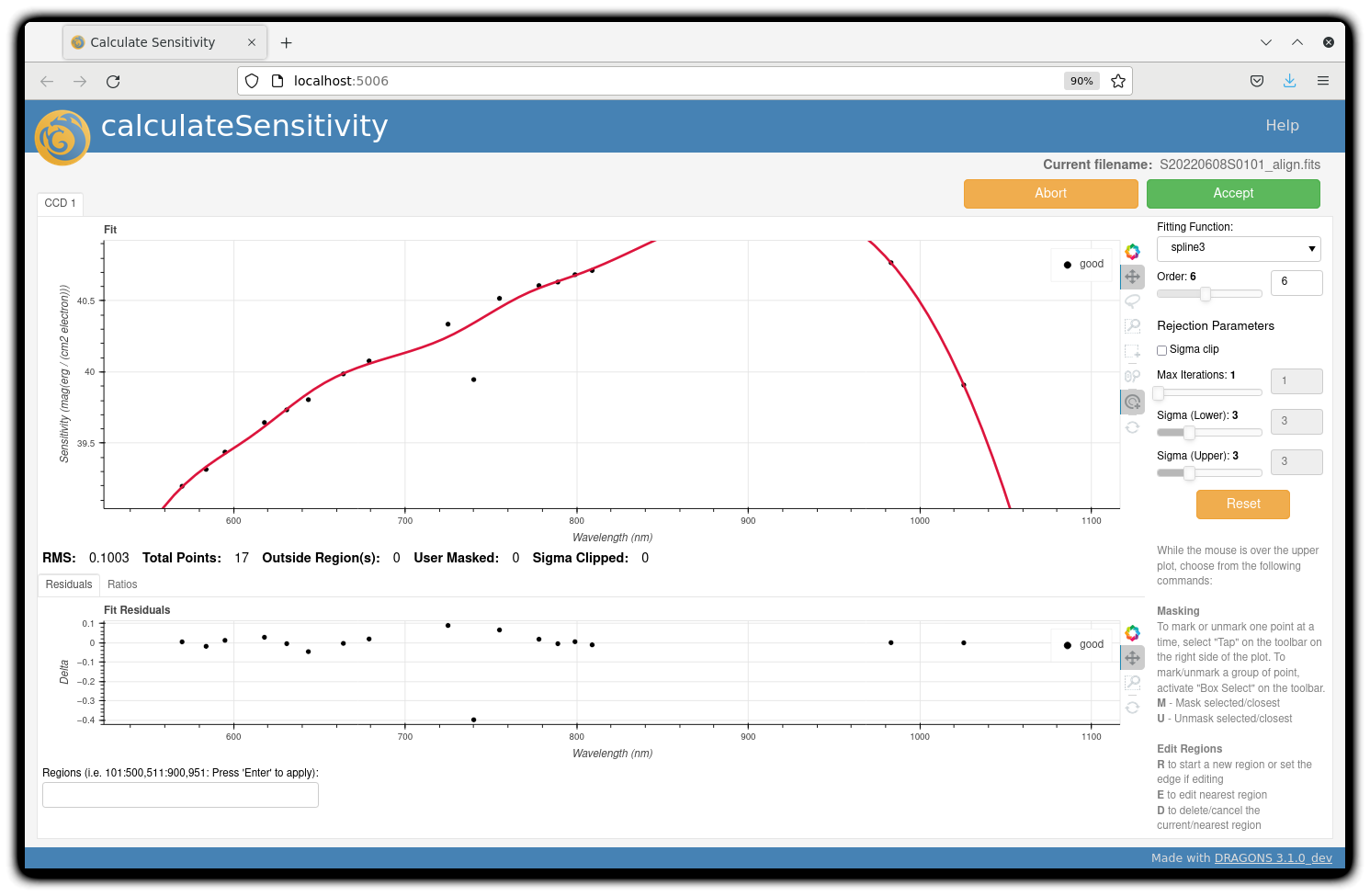
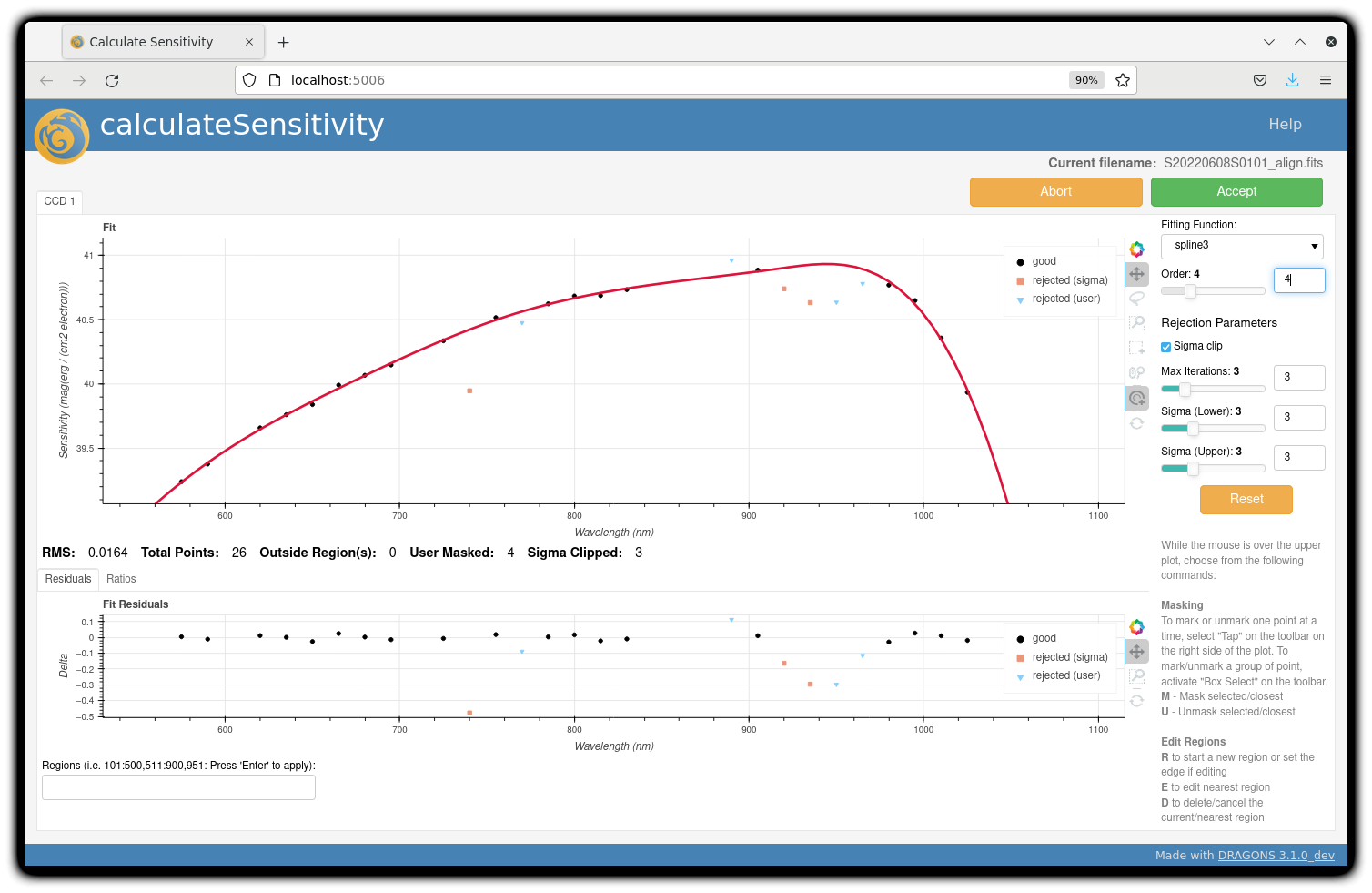
Note
If you wish to inspect the spectrum in aperture 1:
from gempy.adlibrary import plotting
ad = astrodata.open(reduce_std_795nm.output_filenames[0])
plotting.dgsplot_bokeh(ad, 1)
To learn how to plot a 1-D spectrum with matplotlib using the WCS from a Python script, see Tips and Tricks Plot a 1-D spectrum.
The sensitivity function is stored within the processed standard spectrum. To learn how to plot it, see Tips and Tricks Inspect the sensitivity function.
5.3.9. Science Observations
As mentioned previously, the science target is the central galaxy of an Odd Radio Circle. The sequence has two images that were dithered in wavelength (with a large step of 90 nm). DRAGONS will register the two images, align and stack them before extracting the 1-D spectrum.
This is what one raw image looks like.

The broad, white and black vertical bands (slightly to the left of the middle) are related to the GMOS-S amplifier #5 issues. As can be seen, there are two obvious sources in this observation. Regardless of whether both of them are of interest to the program, DRAGONS will locate, trace, and extract them automatically. Each extracted spectrum is stored in an individual extension in the output multi-extension FITS file.
With the master bias, the master flat, the processed arcs (one for each of the grating position, aka central wavelength), and the processed standards in the local calibration manager, one only needs to do as follows to reduce the science observations and extract the 1-D spectrum.
98reduce_science = Reduce()
99reduce_science.files.extend(scitarget)
100reduce_science.recipename = 'reduceWithMultipleStandards'
101reduce_science.uparms = dict([('interactive', True)])
102reduce_science.runr()
Here we use a different science reduction recipe reduceWithMultipleStandards (line 97)
than the default. The
latter performs flux calibration after stacking the extracted spectra
as described here, which is not suitable
for these observations with a large wavelength dither. The recipe
reduceWithMultipleStandards will run flux calibration for each
central wavelength using the corresponding sensitivity function from the
spectrophotometric standard before stacking
the observations – the desired workflow for this example.
You can make use of the interactive tools to optimize the reduction. For the science reduction above, we have deleted any additional apertures found by DRAGONS barring the two most prominent ones (see the left plot; click to enlarge). You simply hover over the unwanted peak and press D. Furthermore, we have selected sigma-clipping while tracing the apertures (right plot; click to enlarge). Notice that there is an additional tab for Aperture 2 in the upper part of the right plot.
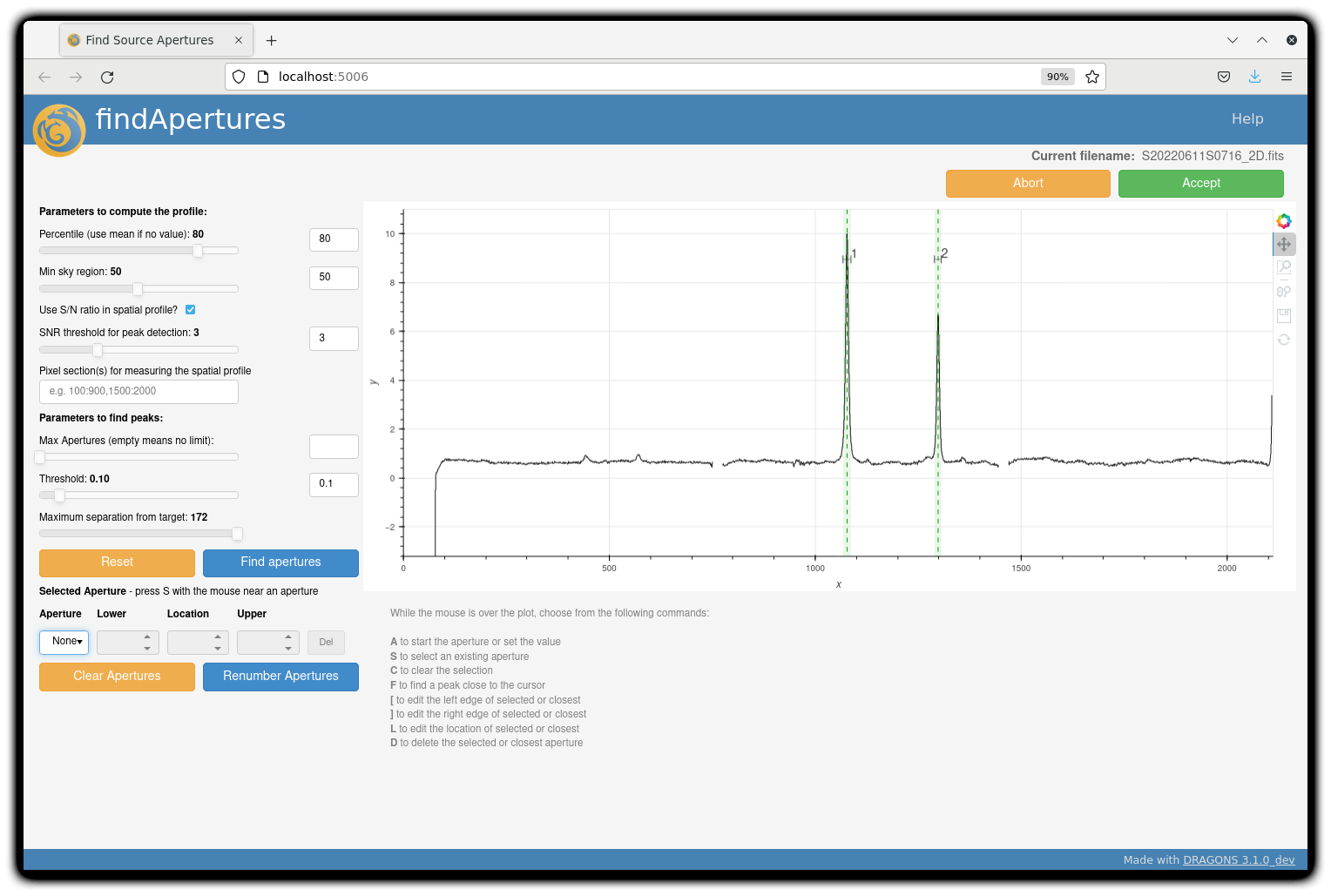
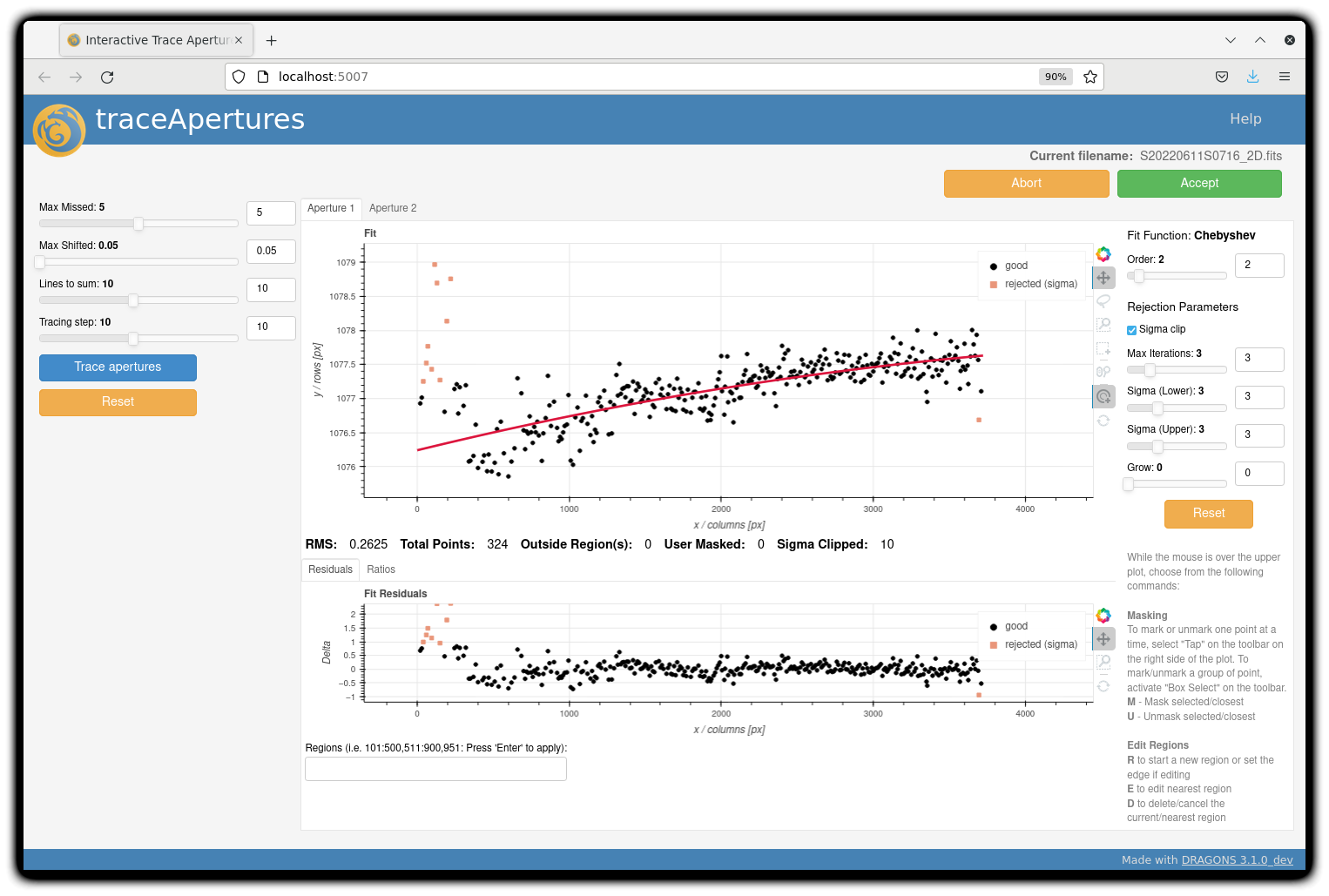
The outputs include a 2-D spectrum image (S20220611S0716_2D.fits), which has been
bias corrected, flat fielded, QE-corrected, wavelength-calibrated, corrected for
distortion, sky-subtracted, flux-calibrated, and stacked, and also the 1-D spectra
(S20171022S0087_1D.fits) extracted from this 2-D spectrum image. The 1-D spectra are stored
as 1-D FITS images in extensions of the output Multi-Extension FITS file, along with their
respective variance and data quality (or mask) arrays.
Note
If you wish to inspect the content of the 1-D output, run:
astrodata.open('S20220611S0716_1D.fits').info()
Filename: S20220611S0716_1D.fits
Tags: EXTRACTED GEMINI GMOS LS OVERSCAN_SUBTRACTED OVERSCAN_TRIMMED PREPARED
PROCESSED PROCESSED_SCIENCE SIDEREAL SOUTH SPECT
Pixels Extensions
Index Content Type Dimensions Format
[ 0] science NDAstroData (3743,) float32
.variance ADVarianceUncerta (3743,) float32
.mask ndarray (3743,) uint16
[ 1] science NDAstroData (3743,) float32
.variance ADVarianceUncerta (3743,) float32
.mask ndarray (3743,) uint16
Other Extensions
Type Dimensions
.PROVENANCE Table (10, 4)
.HISTORY Table (24, 4)
This is what the 2-D spectrum image looks like.
103display = Reduce()
104display.files = ['S20220611S0716_2D.fits']
105display.recipename = 'display'
106display.runr()
Note
ds9 must be launched by the user ahead of running the display primitive.
(ds9& on the terminal prompt.)

The apertures found are listed in the log for the findApertures primitive,
just before the call to traceApertures. Information about the apertures
are also available in the header of each extracted spectrum: XTRACTED,
XTRACTLO, XTRACTHI, for aperture center, lower limit, and upper limit,
respectively.
The 1-D flux-calibrated spectra of the two apertures are shown below.
107from gempy.adlibrary import plotting
108
109ad = astrodata.open(reduce_science.output_filenames[0])
110plotting.dgsplot_bokeh(ad, 1)
111plotting.dgsplot_bokeh(ad, 2)
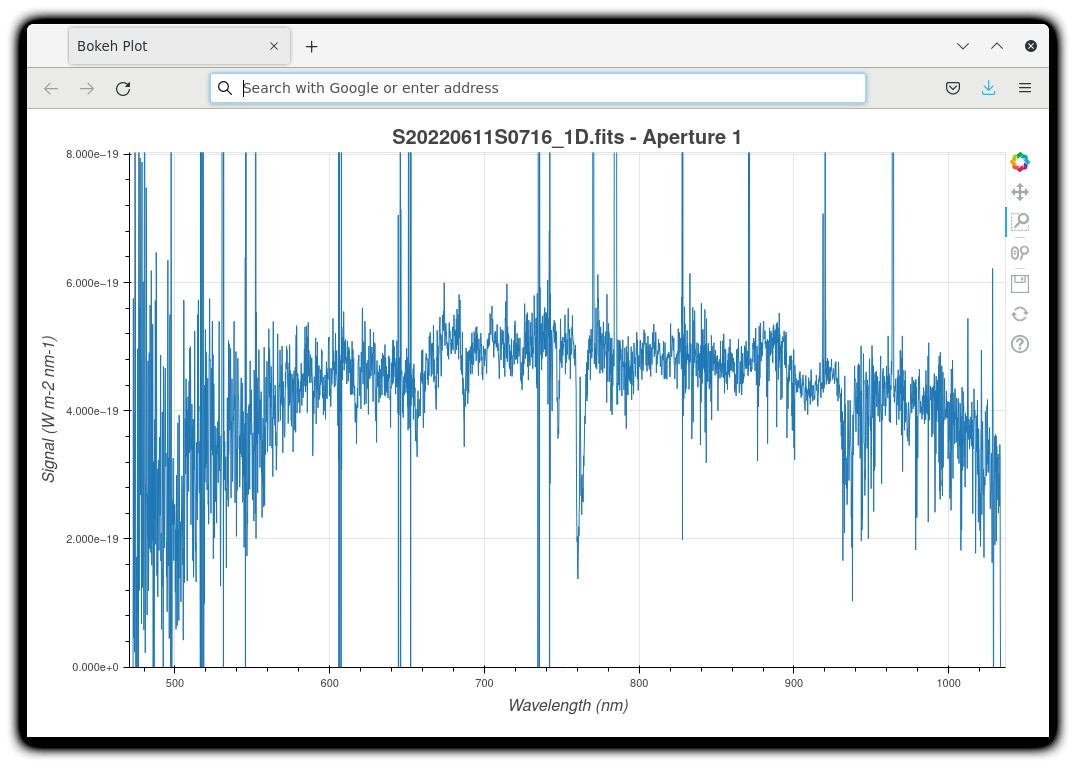
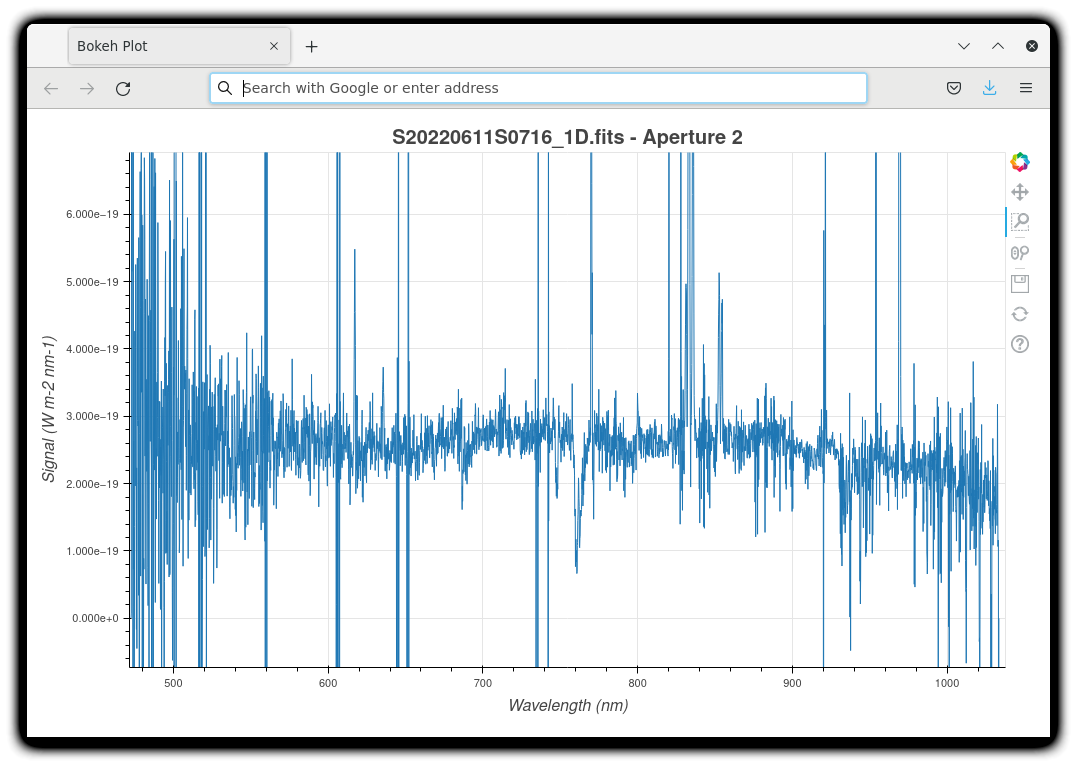
To learn how to plot a 1-D spectrum with matplotlib using the WCS from a Python script, see Tips and Tricks Plot a 1-D spectrum.
If you need an ascii representation of the spectum, you can use the primitive
write1DSpectra to extract the values from the FITS file.
115writeascii = Reduce()
116writeascii.files = ['S20220611S0716_1D.fits']
117writeascii.recipename = 'write1DSpectra'
118writeascii.runr()
The primitive outputs in the various formats offered by astropy.Table. To
see the list, use showpars from the command line.
showpars S20220611S0716_1D.fits write1DSpectra
To use a different format, set the format parameters.
119writeascii = Reduce()
120writeascii.files = ['S20220611S0716_1D.fits']
121writeascii.recipename = 'write1DSpectra'
122writeascii.uparms = dict([('format', 'ascii.ecsv'), ('extension', 'ecsv')])
123writeascii.runr()