7.3. Example 4 - Nod-and-Shuffle Correct for Extra Order - Using the “Reduce” class
A reduction can be initiated from the command line as shown in Example 4 - Nod-and-Shuffle Correct for Extra Order - Using the “reduce” command line and it can also be done programmatically as we will show here. The classes and modules of the RecipeSystem can be accessed directly for those who want to write Python programs to drive their reduction. In this example we replicate the command line version of Example 4 but using the Python programmatic interface. What is shown here could be packaged in modules for greater automation.
In this example we will reduce a GMOS longslit nod-and-shuffle observation of a high redshift quasar. The particularity here is that the setting is quite red and the second order shows up in the spectrum. The configuration uses the OG515 blocking filter and the second order light appears at 1030nm. We will show how to recognize the effect and then how to not include the light from that extra order using the interactive tools.
7.3.1. The dataset
If you have not already, download and unpack the tutorial’s data package. Refer to Downloading tutorial datasets for the links and simple instructions.
The dataset specific to this example is described in:
Here is a copy of the table for quick reference.
Science |
N20080830S0261 (900 nm)
N20080830S0262 (890 nm)
N20080830S0265 (880 nm)
|
Science biases |
N20080830S0527-531
|
Science flats |
N20080830S0260 (900 nm)
N20080830S0263 (890 nm)
N20080830S0264 (880 nm)
|
Science arcs |
N20080830S0491 (900 nm)
N20080830S0492 (890 nm)
N20080830S0493 (880 nm)
|
Standard (G191B2B) |
N20190902S0046 (900 nm)
|
Standard biases |
N20081011S0313-317
|
Standard flats |
N20081010S0534 (900 nm)
|
Standard arc |
N20081010S0552 (900 nm)
|
BPM |
bpm_20010801_gmos-n_EEV_22_full_3amp.fits
|
7.3.2. Setting up
First, navigate to your work directory in the unpacked data package.
cd <path>/gmosls_tutorial/playground
The first steps are to import libraries, set up the calibration manager, and set the logger.
7.3.2.1. Configuring the interactive interface
In ~/.dragons/, add the following to the configuration file dragonsrc:
[interactive]
browser = your_prefered_browser
The [interactive] section defines your prefered browser. DRAGONS will open
the interactive tools using that browser. The allowed strings are “safari”,
“chrome”, and “firefox”.
7.3.2.2. Importing libraries
1import glob
2
3import astrodata
4import gemini_instruments
5from recipe_system.reduction.coreReduce import Reduce
6from gempy.adlibrary import dataselect
The dataselect module will be used to create file lists for the
biases, the flats, the arcs, the standard, and the science observations.
The Reduce class is used to set up and run the data
reduction.
7.3.2.3. Setting up the logger
We recommend using the DRAGONS logger. (See also Double messaging issue.)
7from gempy.utils import logutils
8logutils.config(file_name='gmosls_tutorial.log')
7.3.2.4. Set up the Calibration Service
Important
Remember to set up the calibration service.
Instructions to configure and use the calibration service are found in Setting up the Calibration Service, specifically the these sections: The Configuration File and Usage from the API.
7.3.3. Create file lists
The next step is to create input file lists. The module dataselect helps
with that. It uses Astrodata tags and descriptors to select the files and
store the filenames to a Python list that can then be fed to the Reduce
class. (See the Astrodata User Manual for information about Astrodata and for a list
of descriptors.)
The first list we create is a list of all the files in the playdata
directory.
9all_files = glob.glob('../playdata/example4/*.fits')
10all_files.sort()
We will search that list for files with specific characteristics. We use
the all_files list as an input to the function
dataselect.select_data() . The function’s signature is:
select_data(inputs, tags=[], xtags=[], expression='True')
We show several usage examples below.
7.3.3.1. Two lists for the biases
We have two sets for biases: one for the science observation, one for the spectrophotometric standard observation. The science observations and the spectrophotometric standard observations were obtained using different regions-of-interest (ROI). So we will need two master biases, one “Full Frame” for the science and one “Central Spectrum” for the standard.
To inspect data for specific descriptors, and to figure out how to build
our dataselect expression, we can loop through the biases and print the value
for the descriptor of interest, here detector_roi_setting.
11all_biases = dataselect.select_data(all_files, ['BIAS'])
12for bias in all_biases:
13 ad = astrodata.open(bias)
14 print(bias, ' ', ad.detector_roi_setting())
../playdata/example4/N20080830S0527.fits Full Frame
../playdata/example4/N20080830S0528.fits Full Frame
../playdata/example4/N20080830S0529.fits Full Frame
../playdata/example4/N20080830S0530.fits Full Frame
../playdata/example4/N20080830S0531.fits Full Frame
../playdata/example4/N20081011S0313.fits Central Spectrum
../playdata/example4/N20081011S0314.fits Central Spectrum
../playdata/example4/N20081011S0315.fits Central Spectrum
../playdata/example4/N20081011S0316.fits Central Spectrum
../playdata/example4/N20081011S0317.fits Central Spectrum
We can clearly see the two groups of biases above. Let’s split them into two lists.
15biasstd = dataselect.select_data(
16 all_files,
17 ['BIAS'],
18 [],
19 dataselect.expr_parser('detector_roi_setting=="Central Spectrum"')
20)
21
22biassci = dataselect.select_data(
23 all_files,
24 ['BIAS'],
25 [],
26 dataselect.expr_parser('detector_roi_setting=="Full Frame"')
27)
Note
All expressions need to be processed with dataselect.expr_parser.
7.3.3.2. A list for the darks
Nod-and-shuffle darks are required for the reduction of nod-and-shuffle observations obtained with the EEV CCDs (this case) and the ee2vv CCDs.
28darks = dataselect.select_data(all_files, ['DARK'])
7.3.3.3. A list for the flats
The GMOS longslit flats are not normally stacked. The default recipe does not stack the flats. This allows us to use only one list of the flats. Each will be reduced individually, never interacting with the others.
The flats used for nod-and-shuffle are normal flats. The DRAGONS recipe will “double” the flat and apply it to each beam.
29flats = dataselect.select_data(all_files, ['FLAT'])
7.3.3.4. A list for the arcs
The GMOS longslit arcs are not normally stacked. The default recipe does not stack the arcs. This allows us to use only one list of arcs. Each will be reduce individually, never interacting with the others.
30arcs = dataselect.select_data(all_files, ['ARC'])
7.3.3.5. A list for the spectrophotometric standard star
If a spectrophotometric standard is recognized as such by DRAGONS, it will
receive the Astrodata tag STANDARD. To be recognized, the name of the
star must be in a lookup table. All spectrophotometric standards normally used
at Gemini are in that table.
31stdstar = dataselect.select_data(all_files, ['STANDARD'])
7.3.3.6. A list for the science observation
The science observations are what is left, that is anything that is not a
calibration. Calibrations are assigned the astrodata tag CAL, therefore
we can select against that tag to get the science observations.
First, let’s have a look at the list of objects.
32all_science = dataselect.select_data(all_files, [], ['CAL'])
33for sci in all_science:
34 ad = astrodata.open(sci)
35 print(sci, ' ', ad.object())
On line 32, remember that the second argument contains the tags to include
(tags) and the third argument is the list of tags to exclude
(xtags).
../playdata/example4/N20080830S0261.fits 433819088548
../playdata/example4/N20080830S0262.fits 433819088548
../playdata/example4/N20080830S0265.fits 433819088548
In this case we only have one target. If we had more than one, we would need
several lists and we could use the object descriptor in an expression. We
will do that here to show how it would be done. To be clear, the
dataselect.expr_parser argument is not necessary in this specific case.
36scitarget = dataselect.select_data(all_files, [], ['CAL'])
7.3.4. Bad Pixel Mask
Starting with DRAGONS v3.1, the static bad pixel masks (BPMs) are now handled as calibrations. They are downloadable from the archive instead of being packaged with the software. They are automatically associated like any other calibrations. This means that the user now must download the BPMs along with the other calibrations and add the BPMs to the local calibration manager.
See Getting Bad Pixel Masks from the archive in Tips and Tricks to learn about the various ways to get the BPMs from the archive.
To add the BPM included in the data package to the local calibration database:
37for bpm in dataselect.select_data(all_files, ['BPM']):
38 caldb.add_cal(bpm)
7.3.5. Master Bias
We create the master biases with the Reduce class. We will run it
twice, once for each of the two raw bias lists. The master biases
will be automatically added to the local calibration manager when the “store”
parameter is present in the .dragonsrc configuration file.
The output is written to disk and its name is stored in the Reduce
instance. The calibration service expects the name of a file on disk.
Because the database was given the “store” option in the dragonsrc file,
the processed biases will be automatically added to the database at the end
of the recipe.
39reduce_biasstd = Reduce()
40reduce_biassci = Reduce()
41reduce_biasstd.files.extend(biasstd)
42reduce_biassci.files.extend(biassci)
43reduce_biasstd.runr()
44reduce_biassci.runr()
The two master biases are: N20081011S0313_bias.fits and
N20080830S0527_bias.fits.
Note
The file name of the output processed bias is the file name of the
first file in the list with _bias appended as a suffix. This is the
general naming scheme used by the Recipe System.
Note
If you wish to inspect the processed calibrations before adding them
to the calibration database, remove the “store” option attached to the
database in the dragonsrc configuration file. You will then have to
add the calibrations manually following your inspection, eg.
caldb.add_cal(reduce_biasstd.output_filenames[0])
caldb.add_cal(reduce_biassci.output_filenames[0])
7.3.6. Master Nod-and-Shuffle Dark
The nod-and-shuffle darks normally reproduced the same number of charge shuffling as was done for the science data observation. They are done during the day, when daytime work allows, or at night when the weather is bad. This set was obtained 2 months after the science data.
The darks are stacked together. Here we use the same bias as for the science observation to minimize the amount of data required to download for this tutorial. For a science reduction, it might beneficial to use biases that are contemporary to the darks (ie. from around 2008-10-26).
45reduce_darks = Reduce()
46reduce_darks.files.extend(darks)
47reduce_darks.runr()
7.3.7. Master Flat Field
GMOS longslit flat fields are normally obtained at night along with the observation sequence to match the telescope and instrument flexure. The matching flat nearest in time to the target observation is used to flat field the target. The central wavelength, filter, grating, binning, gain, and read speed must match.
Because of the flexure, GMOS longslit flat fields are not stacked. Each is reduced and used individually. The default recipe takes that into account.
We can send all the flats, regardless of characteristics, to Reduce and each
will be reduce individually. When a calibration is needed, in this case, a
master bias, the best match will be obtained automatically from the local
calibration manager.
48reduce_flats = Reduce()
49reduce_flats.files.extend(flats)
50reduce_flats.runr()
7.3.8. Processed Arc - Wavelength Solution
GMOS longslit arc can be obtained at night with the observation sequence, if requested by the program, but are often obtained at the end of the night or the following afternoon instead. In this example, the arcs have been obtained at night, as part of the sequence. Like the spectroscopic flats, they are not stacked which means that they can be sent to reduce all together and will be reduced individually.
The wavelength solution is automatically calculated and the algorithm has
been found to be quite reliable. There might be cases where it fails; inspect
the *_wavelengthSolutionDetermined.pdf plot and the RMS of determineWavelengthSolution in the
logs to confirm a good solution.
51reduce_arcs = Reduce()
52reduce_arcs.files.extend(arcs)
53reduce_arcs.runr()
7.3.9. Processed Standard - Sensitivity Function
The GMOS longslit spectrophotometric standards are normally taken when there is a hole in the queue schedule, often when the weather is not good enough for science observations. One standard per configuration, per program is the norm. If you dither along the dispersion axis, most likely only one of the positions will have been used for the spectrophotometric standard. This is normal for baseline calibrations at Gemini. The standard is used to calculate the sensitivity function. It has been shown that a difference of 10 or so nanometers does not significantly impact the spectrophotometric calibration.
The reduction of the standard will be using a BPM, a master bias, a master flat,
and a processed arc. If those have been added to the local calibration
manager, they will be picked up automatically. The output of the reduction
includes the sensitivity function and will be added to the calibration
database automatically if the “store” option is set in the dragonsrc
configuration file.
54reduce_std = Reduce()
55reduce_std.files.extend(stdstar)
56reduce_std.uparms = dict([('traceApertures:interactive', True),
57 ('calculateSensitivity:interactive', True)])
58reduce_std.runr()
The interactive tools are introduced in a later chapter: Interactive tools. Here we will focus on two of them, the one for the trace and the one for the calculation of the sensitivity function.
In both cases, we will adjust the region to use for the fits. This is done by pointing the cursor on one edge of the region, typing “r”, moving the cursor to the other edge, and typing “r” again. To adjust the edge of an existing region, use “e” and the cursor, and “e” again to confirm the adjustment. See the summary of keyboard shortcuts at the bottom right of the tool, in gray font.
It is also possible to set regions using the “Regions” textbox below the plots.
traceApertures
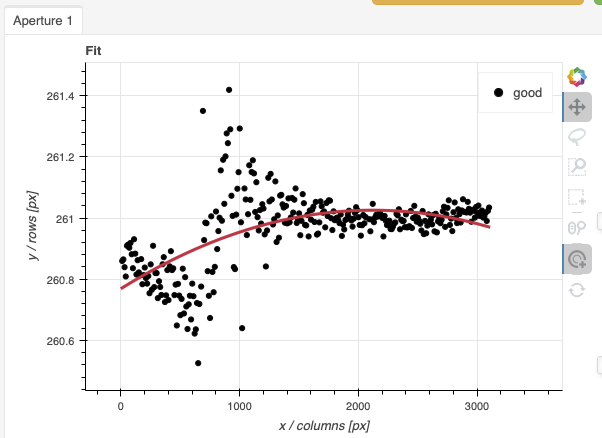
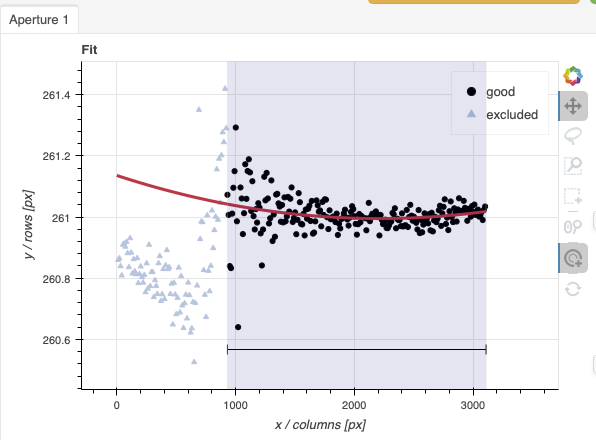
Here are the before and after fits. The x-axis is in pixels with the red-end to the left, the blue-end to the right. You can see the sharp discontinuity around pixel 1000. The points to left of the discontinuity are from the second order. The flux from the first order (right of discontinuity) fades away, and the second order takes over.
We want the trace to follow the first order light only. The region in gray is what we need to define. Using just those points, the trace matches the first order light much better.
calculateSensitivity
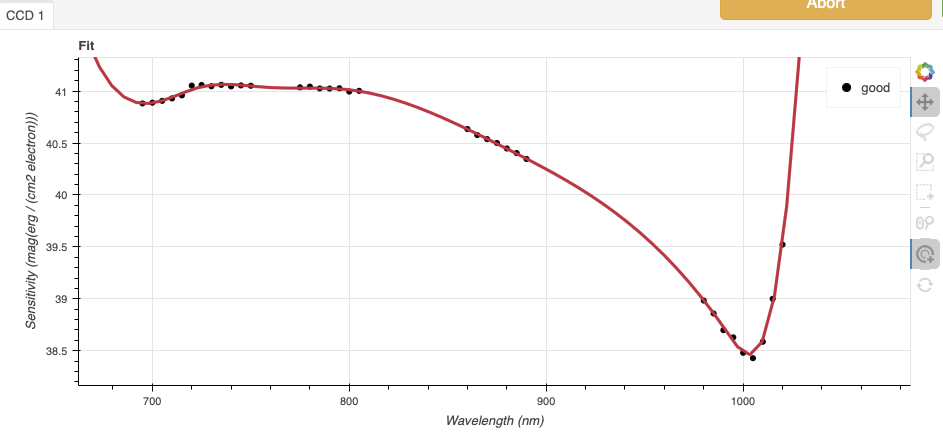
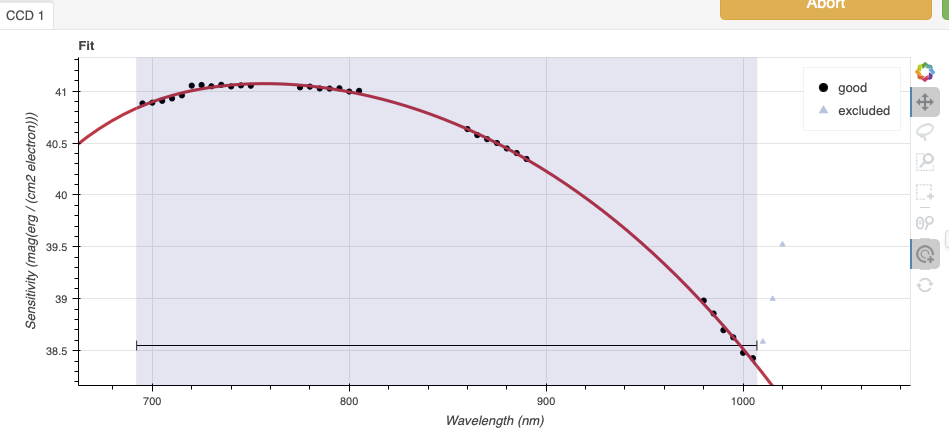
Again, here are the before and after fits. The x-axis this time is in wavelength with the blue-end to the left and the red-end to the right. The fits is good within the region that covers the first order. But there is some flaring at both ends with some on the red side due to our previous cut not being aggressive enough.
Like we did for the trace, we can define a region to use for the fit, this is the gray area on the “after” plot. Another thing that was adjusted is the order of the fit. The default is set to 6, and to avoid flaring on the blue-end, we can reduce the order to 4 to have the smooth function shown here.
7.3.10. Science Observations
The sequence has three images that were dithered along the dispersion axis. DRAGONS will remove the sky from the three images using the nod-and-shuffle beams. The resulting 2D spectra will then be register and stacked before extraction.
This is what one raw image looks like.

With the master bias, the master flat, the processed arcs (one for each of the grating position, aka central wavelength), and the processed standard in the local calibration manager, one only needs to do as follows to reduce the science observations and extract the 1-D spectrum.
59reduce_science = Reduce()
60reduce_science.files.extend(scitarget)
61reduce_science.uparms = dict([('traceApertures:interactive', True)])
62reduce_science.runr()
traceApertures
Below are the before and after adjustments plots. The x-axis is in pixel
like before for the spectrophotometric standard but this time, the data has
been resampled (for the stacking) before traceApertures is called.
Because of that, blue is left and red is right.
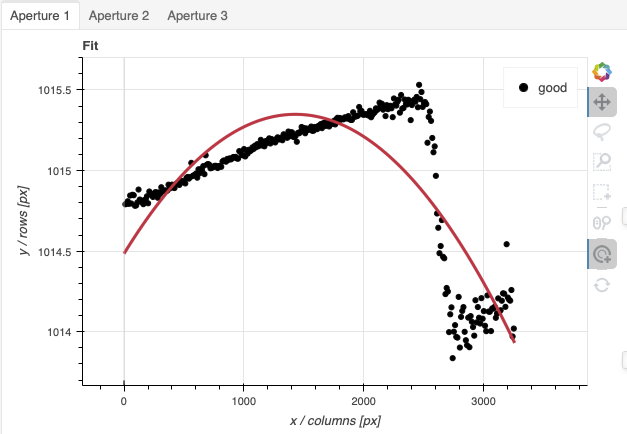
A sharp discontinuity is visible where the first order fades away and the second order starts showing up, around pixel 2600. We set the region to use only the first order light, the points left of the discontinuity.
This time however note that there are three apertures. You can see a tab for each one in the upper part of the plot. If you were not interested in the other, fainter sources, you could ignore them. But if the fainter sources were of interest, you would want to apply the same region to Aperture 2 and 3. The easiest way to do that is to set the region for Aperture 1, and then go to the “Regions” box at the bottom, copy the region, and then paste that region definition in the “Regions” box in the other two tabs.
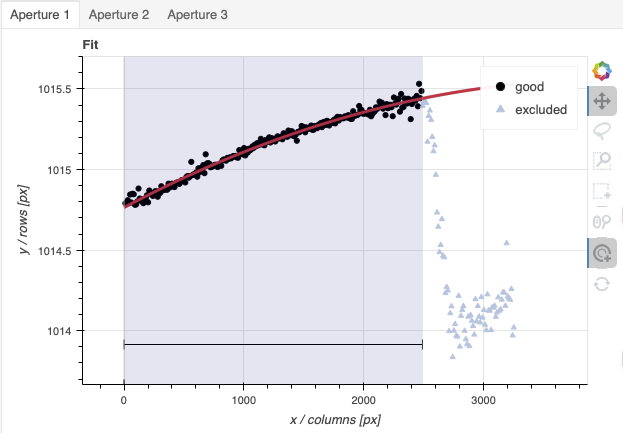
When done, click the green Accept button and the reduction will complete.
The product includes a 2-D spectrum (N20080830S0261_2D.fits) which has been
bias corrected, flat fielded, QE-corrected, wavelength-calibrated, corrected for
distortion, sky-subtracted, the beams combined, and then all frames stacked.
It also produces the 1-D spectrum (N20080830S0261_1D.fits) extracted
from that 2-D spectrum. The 1-D spectrum is flux calibrated with the
sensitivity function from the spectrophotometric standard. The 1-D spectra
are stored as 1-D FITS images in extensions of the output Multi-Extension
This is what the 2-D spectrum looks like. Only the middle section is valid.
63display = Reduce()
64display.files = ['N20080830S0261_2D.fits']
65display.recipename = 'display'
66display.runr()
Note
ds9 must be launched by the user ahead of running the display primitive.
(ds9& on the terminal prompt.)

The apertures found are listed in the log for the findApertures primitive,
just before the call to traceApertures. Information about the apertures
are also available in the header of each extracted spectrum: XTRACTED,
XTRACTLO, XTRACTHI, for aperture center, lower limit, and upper limit,
respectively.
This is what the 1-D flux-calibrated spectrum of our sole target looks like.
67from gempy.adlibrary import plotting
68import matplotlib.pyplot as plt
69
70ad = astrodata.open(reduce_science.output_filenames[0])
71plt.ioff()
72plotting.dgsplot_matplotlib(ad, 1, kwargs={})
73plt.ion()
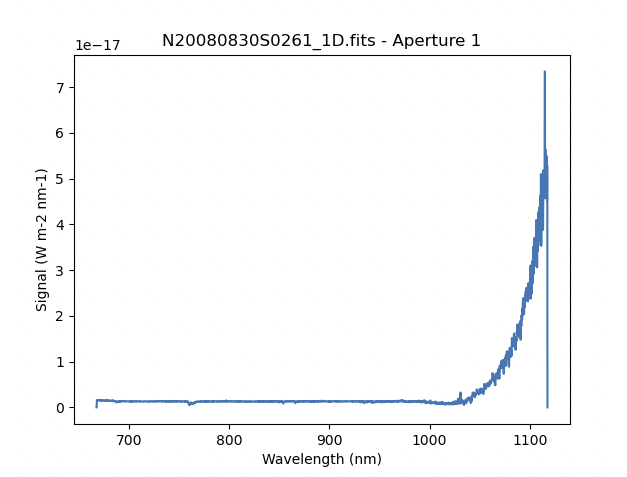
The entire spectrum is plotted including the part redder of the discontinuity where there is no light at all from the first order. What is there is whatever got caught in the extraction that followed the extrapolated trace.
The scaling of the plot is obviously wrong, but we can use the matplotlib interactive zooming feature to focus on the spectrum from the first order. That is shown in the plot on the right.
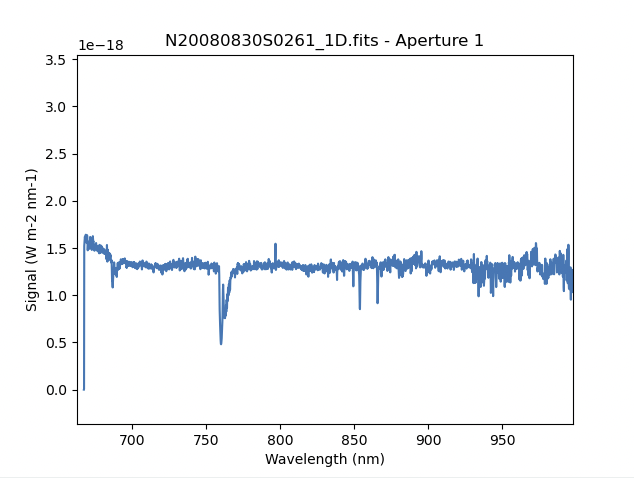
Note the flaring bluer of 700nm. This is because the spectrophotometric
standard was observed with a central wavelength of 900nm and it is unable
to constrain the sensitivity bluer of ~700nm. This can be seen in the
plots of the interactive calculateSensitivity, the bluest point is at 690nm.
(Processed Standard - Sensitivity Function) We have a science spectrum bluer of 690nm because of the other two central
wavelength settings of 890nm and 880nm. Observing the standard with a
central wavelength of 880nm would have help reduce, possible avoid it entirely.