3.3. Example 1 - Star field with dithers - Using the “Reduce” class
A reduction can be initiated from the command line as shown in Example 1 - Star field with dithers - Using the “reduce” command line and it can also be done programmatically as we will show here. The classes and modules of the RecipeSystem can be accessed directly for those who want to write Python programs to drive their reduction. In this example we replicate the command line version of Example 1 but using the Python programmatic interface. What is shown here could be packaged in modules for greater automation.
3.3.1. The dataset
If you have not already, download and unpack the tutorial’s data package. Refer to Downloading the tutorial datasets for the links and simple instructions.
The dataset specific to this example is described in:
Here is a copy of the table for quick reference.
Science |
N20170614S0201-205
|
10 s, i-band
|
Bias |
N20170613S0180-184
N20170615S0534-538
|
|
Twilight Flats |
N20170702S0178-182
|
40 to 16 s, i-band
|
BPM |
bpm_20170306_gmos-n_Ham_22_full_12amp.fits
|
|
3.3.2. Setting Up
3.3.2.1. Importing Libraries
We first import the necessary modules and classes:
1import glob
2
3import astrodata
4import gemini_instruments
5from recipe_system.reduction.coreReduce import Reduce
6from gempy.adlibrary import dataselect
The dataselect module will be used to create file lists for the
biases, the flats, the arcs, the standard, and the science observations.
The Reduce class is used to set up and run the data
reduction.
3.3.2.2. Setting up the logger
We recommend using the DRAGONS logger. (See also Double messaging issue.)
7from gempy.utils import logutils
8logutils.config(file_name='gmos_data_reduction.log')
3.3.2.3. Setting up the Calibration Service
Important
Remember to set up the calibration service.
Instructions to configure and use the calibration service are found in Setting up the Calibration Service, specifically the these sections: The Configuration File and Usage from the API.
3.3.3. Create list of files
The next step is to create input file lists. The module dataselect helps
with that. It uses Astrodata tags and descriptors to select the files and
store the filenames to a Python list that can then be fed to the Reduce
class. (See the Astrodata User Manual for information about Astrodata and for a list
of descriptors.)
The first list we create is a list of all the files in the playdata/example1/
directory.
9all_files = glob.glob('../playdata/example1/*.fits')
10all_files.sort()
The sort() method simply re-organize the list with the file names
and is an optional step, but a recommended step. Before you carry on, you might want to do
print(all_files) to check if they were properly read.
We will search that list for files with specific characteristics. We use
the all_files list as an input to the function
dataselect.select_data() . The function’s signature is:
select_data(inputs, tags=[], xtags=[], expression='True')
We show several usage examples below.
3.3.3.1. List of Biases
Let us select the files that will be used to create a master bias:
11list_of_biases = dataselect.select_data(
12 all_files,
13 ['BIAS'],
14 []
15)
Note the empty list [] in line 20. This positional argument receives a list
of tags that will be used to exclude any files with the matching tag from our
selection (i.e., equivalent to the --xtags option).
3.3.3.2. List of Flats
Next we create a list of twilight flats for each filter. The expression specifying the filter name is needed only if you have data from multiple filters. It is not really needed in this case.
16list_of_flats = dataselect.select_data(
17 all_files,
18 ['FLAT'],
19 [],
20 dataselect.expr_parser('filter_name=="i"')
21)
Note
All expressions need to be processed with dataselect.expr_parser.
3.3.3.3. List of Science Data
Finally, the science data can be selected using:
22list_of_science = dataselect.select_data(
23 all_files,
24 [],
25 ['CAL'],
26 dataselect.expr_parser('(observation_class=="science" and filter_name=="i")')
27)
Here we left the tags argument as an empty list and passed the tag
'CAL' as an exclusion tag through the xtags argument.
We also added a fourth argument which is not necessary for our current dataset
but that can be useful for others. It contains an expression that has to be
parsed by dataselect.expr_parser, and which ensures
that we are getting science frames obtained with the i-band filter.
3.3.4. Bad Pixel Mask
Starting with DRAGONS v3.1, the static bad pixel masks (BPMs) are now handled as calibrations. They are downloadable from the archive instead of being packaged with the software. They are automatically associated like any other calibrations. This means that the user now must download the BPMs along with the other calibrations and add the BPMs to the local calibration manager.
See Getting Bad Pixel Masks from the archive in Tips and Tricks to learn about the various ways to get the BPMs from the archive.
To add the BPM included in the data package to the local calibration database:
28for bpm in dataselect.select_data(all_files, ['BPM']):
29 caldb.add_cal(bpm)
3.3.5. Make Master Bias
We create the master bias and add it to the calibration manager as follows:
30reduce_bias = Reduce()
31reduce_bias.files.extend(list_of_biases)
32reduce_bias.runr()
The Reduce class is our reduction
“controller”. This is where we collect all the information necessary for
the reduction. In this case, the only information necessary is the list of
input files which we add to the files attribute. The
Reduce.runr method is where the
recipe search is triggered and where it is executed.
Note
The file name of the output processed bias is the file name of the
first file in the list with _bias appended as a suffix. This is the
general naming scheme used by the Recipe System.
Note
If you wish to inspect the processed calibrations before adding them
to the calibration database, remove the “store” option attached to the
database in the dragonsrc configuration file. You will then have to
add the calibrations manually following your inspection, eg.
caldb.add_cal(reduce_bias.output_filenames[0])
3.3.6. Make Master Flat
We create the master flat field and add it to the calibration database as follows:
33reduce_flats = Reduce()
34reduce_flats.files.extend(list_of_flats)
35reduce_flats.runr()
3.3.7. Make Master Fringe Frame
Warning
The dataset used in this tutorial does not require fringe correction so we skip this step. To find out how to produce a master fringe frame, see Create Master Fringe Frame in the Tips and Tricks chapter.
3.3.8. Reduce Science Images
We use similar statements as before to initiate a new reduction to reduce the science data:
36reduce_science = Reduce()
37reduce_science.files.extend(list_of_science)
38reduce_science.runr()
The output stack units are in electrons (header keyword BUNIT=electrons). The output stack is stored in a multi-extension FITS (MEF) file. The science signal is in the “SCI” extension, the variance is in the “VAR” extension, and the data quality plane (mask) is in the “DQ” extension.
Below are one of the raw images and the final stack:
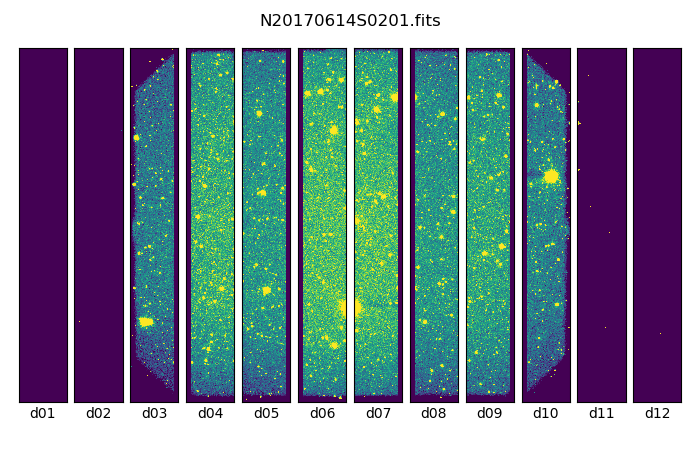
One of the multi-extensions files.
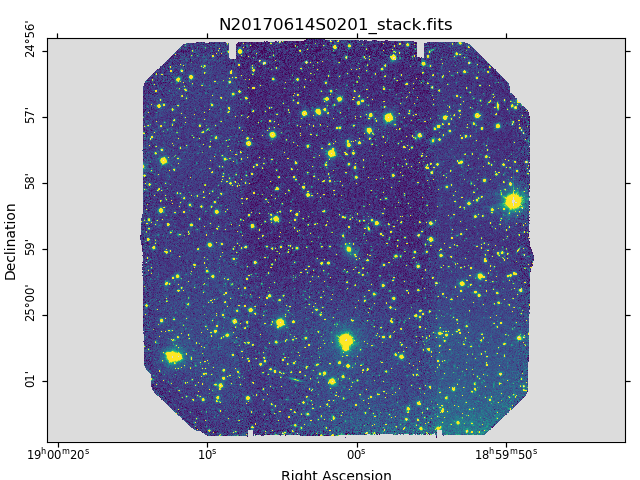
Final stacked image. The light-gray area represents the masked pixels.